







医学部梁臻副教授在IEEE Transactions on Neural Networks and Learning Systems发表针对标签稀缺问题的情感脑机接口研究成果
近日,医学部生物医学工程学院梁臻老师在计算机科学知名期刊IEEE Transactions on Neural Networks and Learning Systems(中科院一区TOP,影响因子10.2)上发表题为“EEGMatch: Learning with Incomplete Labels for Semi-Supervised EEG-based Cross-Subject Emotion Recognition”的论文。香港城市大学博士研究生周如双(18级深圳大学本科生)、深圳大学研究生叶炜珊和哈尔滨工业大学(深圳)张治国教授为共同第一作者,深圳大学梁臻副教授为独立通讯作者。深圳大学为第一作者单位和通讯单位。

脑电图(EEG)作为情绪识别的工具,在情感计算和脑机接口领域具有巨大潜力,但标签数据稀缺仍是其广泛应用的主要障碍。传统的情绪识别方法依赖大量标注数据,标注过程既费时又昂贵。为了解决这一问题,我们提出了一个名为“EEGMatch”的新型半监督迁移学习框架,能够在少量标注数据和大量无标签数据的条件下实现高效情绪解码。
EEGMatch包含三个核心模块:(1)EEG-Mixup数据增强。我们提出了一种新的数据增强方法,通过生成更多有效样本来帮助模型训练。这种方法针对EEG信号的非平稳特性,提升了数据增强的效果,即使标签数据稀缺,也能为模型提供足够的信息。(2)半监督两步配对学习,包括原型级和实例级配对学习。原型级配对通过全局关系捕捉情绪类别特征,实例级配对则关注局部内在关系。这样可以从有限的标签数据中提取情绪的关键特征,尤其在情绪信号复杂时表现出色。(3)半监督多域自适应方法。该方法帮助对齐不同域(如有标签和无标签的数据集)之间的特征表示,减轻了分布失配问题,尤其适用于跨受试者情绪识别,提升模型的泛化能力。通过这三个创新模块,EEGMatch有效解决了EEG情绪识别中的标签稀缺问题,并能在不同受试者间准确识别情绪。
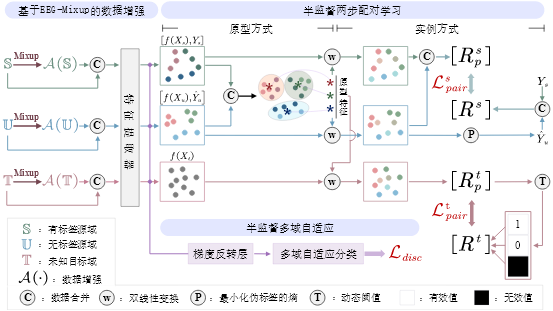
为了验证EEGMatch框架的效果,我们在多个公认的基准数据库(如SEED、SEED-IV、SEED-V)上进行了广泛实验,并采用跨受试者的留一法验证。结果表明,EEGMatch在不同的标签稀缺条件下明显优于现有的先进方法,展示了其在情绪识别中的显著优势,在受限标签条件下的情绪解码任务中具有广阔的应用前景。
EEGMatch的源代码已公开:https://github.com/KAZABANA/EEGMatch。
该研究获得国家自然科学基金等项目资助。
原文链接:https://doi.org/10.1109/TNNLS.2024.3493425
用户登录
还没有账号?
立即注册